免费增值
AI音频/音乐
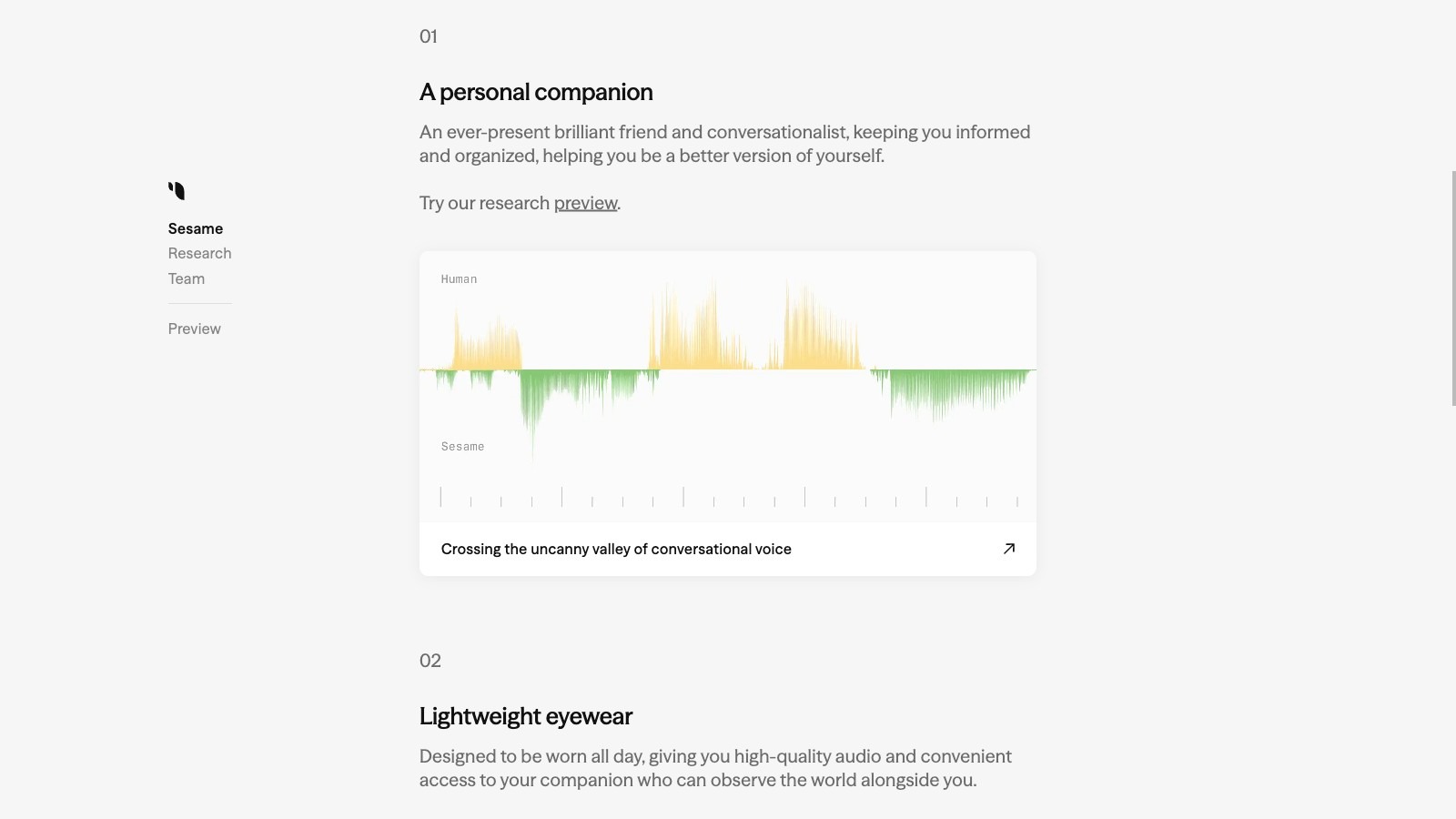
产品简介
Sesame 是一家总部位于旧金山的初创公司,由 Oculus VR 联合创始人 Brendan Iribe 等人创立,专注于“语音临场感”技术。其核心产品是一套端到端、多模态的会话语音模型(Conversational Speech Model,CSM),能够实时生成高度自然、富有情感且上下文连贯的语音。与传统先文本后语音的 TTS 不同,CSM 将文本与音频上下文在同一模型内联合处理,支持多说话人、多语言、情绪识别、语气停顿、笑声及自然填充词,使机器发声更接近真人对话。Sesame AI 已开源 1B 参数的 CSM 版本,并同步提供 Maya、Miles 等虚拟助手演示,面向开发者、企业及内容创作者开放 API/SDK,可用于虚拟助理、客服、教育、娱乐、AR 眼镜等场景。
主要功能
- 实时自然语音合成:端到端模型直接输出高保真语音,延迟低,可边“思考”边说话。
- 多说话人对话支持:同一模型可区分并模拟多位说话人,保持各自音色与个性。
- 情绪与语境感知:根据对话上下文自动调整语调、停顿、笑声及情感强度。
- 多语言及方言覆盖:支持英语、中文、日语、西班牙语等多种语言,发音地道。
- 开源与可扩展架构:提供 Apache 2.0 开源代码、Hugging Face 权重及完整 API/SDK,便于二次开发。
使用方法
- 访问官网 sesame.com 或 GitHub 仓库 SesameAILabs,阅读文档并获取源码。
- 准备 CUDA 12.x GPU、Python 3.10+ 及 ffmpeg,安装依赖并下载模型权重。
- 运行示例脚本,输入文本或音频上下文,生成语音并试听效果。
- 通过 RESTful API 或 Python SDK 将 CSM 集成到自己的应用、游戏或硬件设备。
- 根据业务需求调整语速、音高、情绪强度等参数,上线前进行合规与安全审核。
应用场景
- 虚拟客服与呼叫中心:7×24 小时提供拟人化语音服务,降低人力成本。
- 在线教育与语言学习:为教材、口语练习及 AI 老师赋予生动自然的朗读与对话能力。
- 内容创作与有声读物:快速生成多角色、多情感的配音,缩短制作周期。
- 智能硬件与 AR 眼镜:结合轻量级 AI 眼镜,实现随时随地的语音交互与信息播报。
- 游戏与元宇宙社交:为 NPC 及虚拟化身提供实时、富情感的语音交流体验。